
In cloud computing, cloud storage is a service offering with which a consumer is able to read and write data to cloud-based systems that are managed by a service provider. In this article, which is aimed at those who are new to cloud and computing in general, I discuss the basic concepts you need to understand to get started with storage on AWS.
Cloud storage is usually accessible through a web service or application programming interface (API). The underlying infrastructure is typically a virtualized infrastructure stack with disk drives that are managed by a software service layer.
The most common form of cloud storage is object storage but any method of data management that can be offered as a service across a network can be used. The other cloud storage options are block-based storage and file-based storage and these will all be discussed later in this article.
Storage Concepts
Before we get started on the types of storage available in the cloud and the services offered by AWS, I’d like to provide a review of some basic storage concepts that are important to know before we continue with the rest of the article.
Storage Drive Types and Performance
Hard Disk Drives (HDD) have been around for a long while and are still in widespread use today. A HDD is a mechanical drive with spinning platters and a head that floats above the platters and moves into position to read and write data.

HDDs are also known as magnetic drives as they use magnetic polarization to record a one or zero value.
The performance of a HDD depends on a number of factors and these include the following measurements:
- Revolutions Per Minute (RPM) – the speed of rotation of the platters
- Seek time – the mean time it takes to move the head of a disk drive from one track to another
- Input / Output Operations Per Second (IOPS) – the number of IO transactions per second
- Throughput – the data transfer rate of a drive
HDDs provide good throughput, large capacity, and are extremely low cost.
Solid State Drives (SSD) store data on non-volatile microchips and have no moving parts. Non-volatile SSD chips differ from computer memory in that the data is retained when power is removed.

SSDs offer extremely high IOPS performance when compared to HDDs and also provide good throughput. SSDs are also much more expensive.
Measuring Data
Stored data is typically measured using the decimal system in kilobytes (kB), Megabytes (MB), Gigabytes (GB), Terabytes (TB) and Petabytes (PB).
In some cases the binary prefix is used such as gibibyte (GiB). A gibibyte is equal to 1024 mebibytes (MiB) while a gigabyte (GB) is equal to 1000 megabytes (MB).
To confuse matters a GB of computer memory is equal to 1024 MB (rather than 1000 MB) and some storage manufacturers have been known to use this measurement for disks too.
The following table shows how each term relates to the other in both the decimal and binary formats and the values are the number of bytes (a byte is 8 bits).

The following link provides some more background on this subject:
Data Accessibility SLAs
Cloud service providers will often provide service level agreements (SLAs) for the availability and durability of their storage systems.
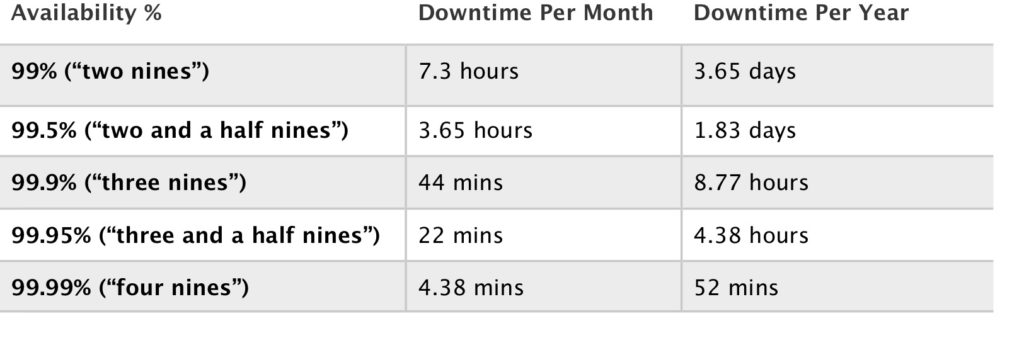
Availability relates to system uptime, i.e. the amount of time per month or year that the storage system is operational and can deliver data upon request. Service providers aim to increase availability by designing highly available and fault tolerant storage systems.
Availability is usually expressed as a percentage of uptime in a given year. The following table shows some common availability SLAs and how much downtime each corresponds with:
Durability relates to measuring the amount of data that may be lost due to errors occurring when writing data. In other words, durability measures the likelihood of losing some of your data.
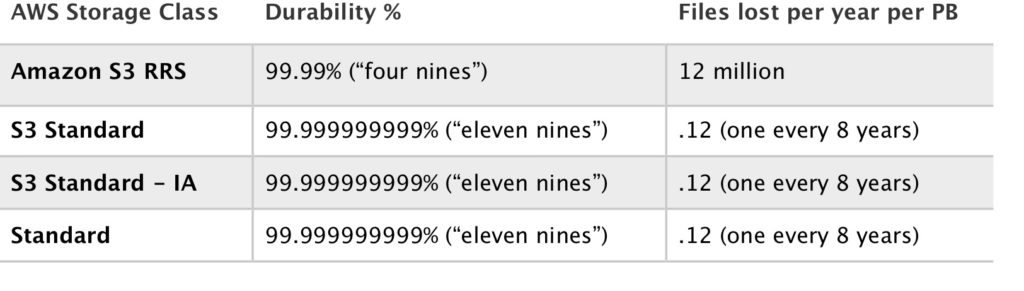
Durability is usually expressed as a percentage of reliability and can also be interpreted as the number of files that are likely to be lost in a given year.
The following table shows the four Amazon Simple Storage Service (S3) storage classes with their respective durability SLAs and how many files could be lost per year:
Cloud Storage Types
As mentioned earlier cloud storage is generally object-based, block-based or file-based storage. These terms relate to the type of data stored, the protocols used to access it, and the method of data storage.
Object Storage
With object storage data is managed as individual objects rather than a file hierarchy (as with a traditional file system). Each object includes the data itself, metadata (data about the data), and a globally unique identifier.
Due to its flat file structure, object storage has virtually unlimited scalability and allows the retention of massive amounts of unstructured data. The data is often replicated across multiple physical systems and facilities providing high availability and durability.
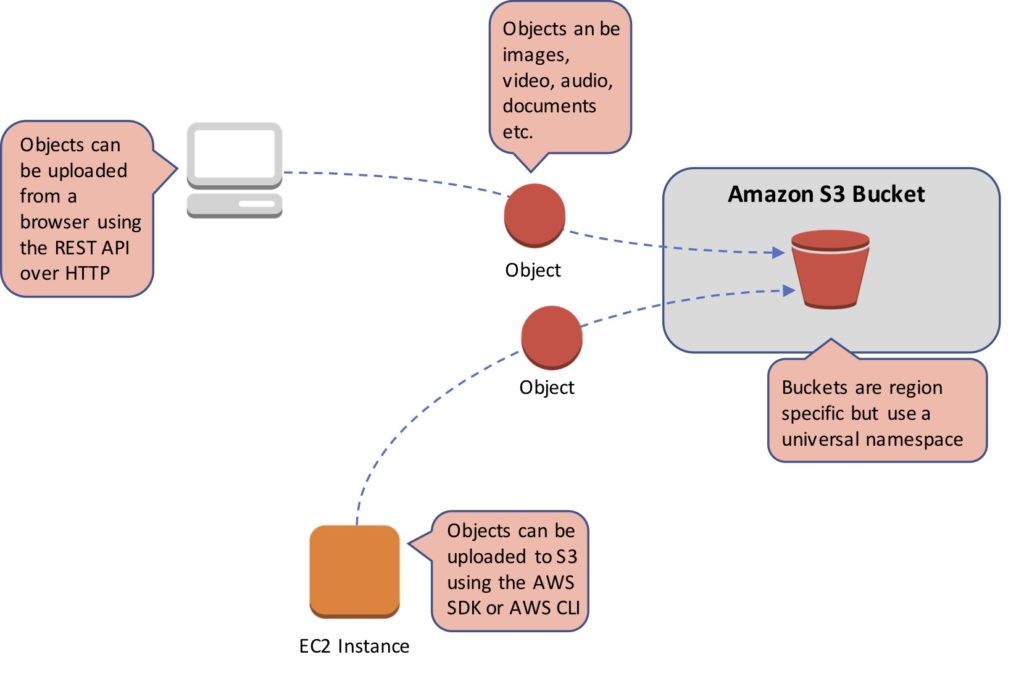
Object storage is usually accessed over Representational State Transfer (REST) and Simple Object Access Protocol (SOAP) over Hypertext Transfer Protocol (HTTP).
The Amazon Simple Storage Service (S3) is a key, value object-based storage system built to store and retrieve huge amounts of data from any source.
Objects in S3 are stored in a flat structure with no hierarchy. The top level containers within which objects are stored are known as buckets. Though there is no hierarchy S3 does support the concept of folders for organization (grouping of objects).
There are several S3 storage classes with varying levels of availability, durability and features. The standard class offers the following features:
- Low latency and high throughput performance
- Designed for durability of 99.999999999% of objects across multiple Availability Zones
- Data is resilient in the event of one entire Availability Zone destruction
- Designed for 99.99% availability over a given year
- Backed with the Amazon S3 Service Level Agreement for availability
- Supports SSL for data in transit and encryption of data at rest
- Lifecycle management for automatic migration of objects
Common use cases for object storage include backup, application hosting, media hosting and software delivery.
Block Storage
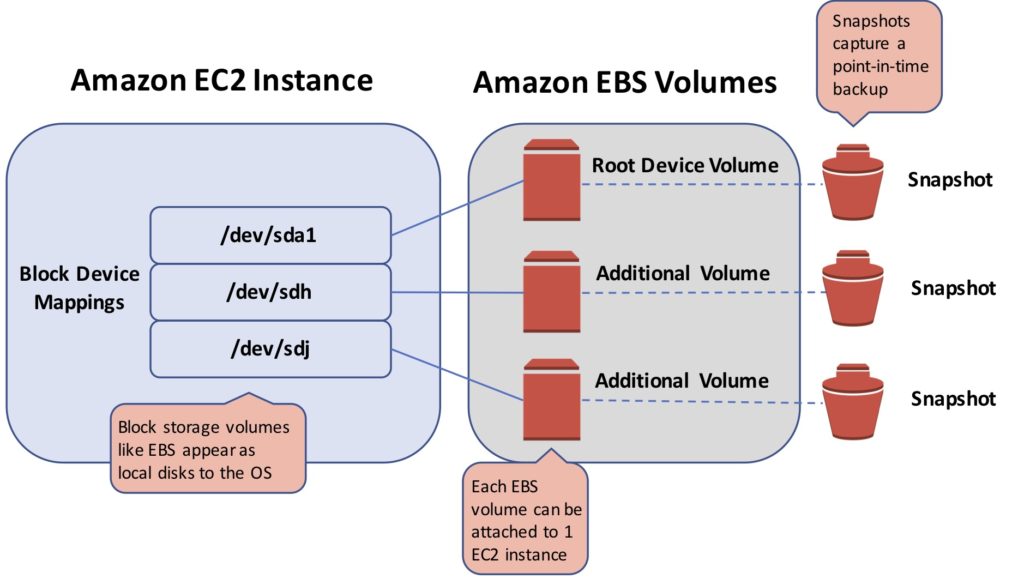
Data is stored and managed in blocks within sectors and tracks and is controlled by a server-based operating system. Block storage volumes appear as local disks to the operating system and can be partitioned and formatted.
Block storage is typically used in Storage Area Network (SAN) environments that use the Fibre Channel (FC) protocol as well as Ethernet networks using protocols such as iSCSI or Fibre Channel over Ethernet (FCoE).
Block storage is typically more expensive than object or file storage but provides low latency, and high and consistent performance. The costs are often highest in SAN implementations due to the specialized equipment required.
Amazon Elastic Block Store (EBS) is the AWS service for block storage. EBS provides persistent block storage volumes for use with EC2 instances in the AWS cloud.
There are several EBS volume types to choose from with varying characteristics as can be seen in the table below:

Common use cases for block storage are structured information such as file systems, databases, transactional logs, SQL databases and virtual machines (VMs).
Though the cloud service provider takes care of many aspects of performance and availability, it is also possible to implement a Redundant Array of Inexpensive Disks (RAID) array on Amazon EBS.
File Storage
File storage servers store data in a hierarchical structure using files and folders. Data is accessed as file IDs across a network using either the Server Message Block (SMB) for Windows, or Network File System (NFS) for Unix/Linux.
A file system is mounted via the network to a client computer where it then becomes accessible for reading and writing data. Files and folders can be created, updated, and deleted.
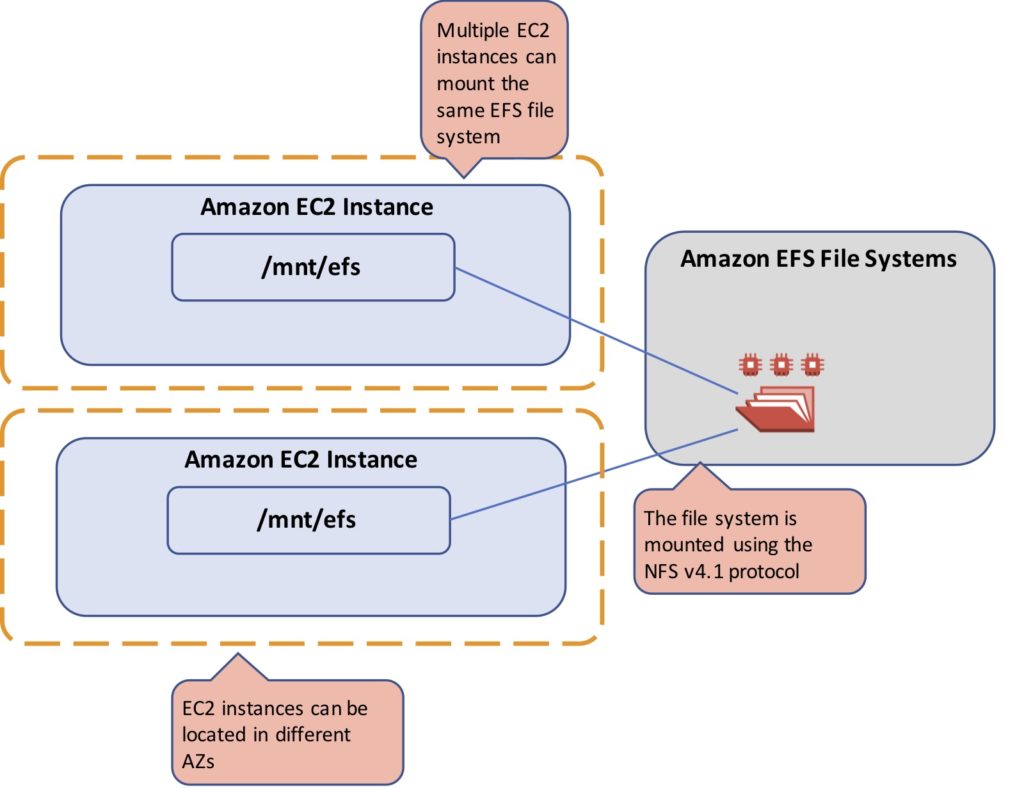
Only file-level operations can occur on a mounted file system, it is not possible to issue block level commands or format or partition the underlying storage volumes.
File storage is easy to implement and use and is generally quite inexpensive. Use cases include web serving and content management, shared corporate directories, home drives, database backups and big data analytics workloads.
The Amazon Elastic File System (EFS) is a simple, scalable, elastic file storage in the AWS cloud that is based on NFS. EFS provides the ability to mount a file system to many EC2 instances simultaneously and can achieve high levels of aggregate throughput and IOPS.
EFS is a regional AWS service and provides high availability and durability by storing data redundantly across Availability Zones (AZs).
More Information
If you would like to learn more about cloud storage on AWS, the following AWS Certified Solutions Architect Associate training notes pages contain a lot more detail:
This article is part of a series, please also check out:
- What is Cloud Computing? Cloud vs Legacy IT
- Cloud Computing Service Models – IaaS, PaaS, SaaS
- Cloud Computing Deployment Models – Public, Private & Hybrid
- Cloud Computing Basics – Compute
- Cloud Computing Basics – Storage
- Cloud Computing Basics – Network
- Cloud Computing Basics – Serverless
Ready to Take Your Tech Career to the Next Level?
- On-Demand Training: Learn at your own pace and on your own schedule.
- Challenge Labs: Apply what you’ve learned in a real-world setting without the risk of incurring surprise cloud bills.
- Cloud Mastery Bootcamp: Build job-ready skills with this live, immersive training that can get you certified faster than you thought possible.