
A basic understanding of serverless cloud computing is becoming increasingly important as this technology has evolved and matured in recent years and has exploded in popularity. Some people are even saying we live in a “post-container” world. No matter the hype, serverless computing is a useful technology that provides significant benefits to developers and organizations.
Where traditional virtualization provides hardware abstraction, and containers abstract the operating system, serverless computing abstracts the runtime environment. This means that developers no longer have to think about server resources when building and deploying applications, allowing them to focus on creating value rather than spending time on operations.
The diagram below depicts the consumer responsibility (and resulting abstractions) when using the Infrastructure as a Service (IaaS), Container as a Service (CaaS) and Functions as a Service (FaaS) cloud services models.

In its essence, serverless computing provides “functions” which provide data processing for your code using many different programming languages. You simply upload your code and it sits dormant until it needs to be executed. You pay for only what you use, and the functions can scale elastically as required.
There is still a server processing the functions of course. However, it is fully managed by the cloud service provider and is not visible to the consumer. Please note there are additional “serverless” computing offerings available other than functions, but this article focuses mainly on functions.
The key benefits of serverless computing include:
- There are no servers to manage
- Fast instantiation of code
- Continuous scaling (elasticity)
- Pay only for what you use
- Completely dynamic (everything is automated)
- Services based (or functions based; ideal for microservices architectures)
- Dynamic access to cloud resources
Use cases for serverless computing include performing real-time data processing for many types of applications, building scalable back-end services that are able to provide self-scaling and to bind and choreograph systems into integration services, applications, and processes.
It’s key to understand that serverless computing is not a good fit for all use case however. The best use cases usually include applications that are net new “cloud-native” architectures, which require elasticity, and that are based on service-oriented architectures such as microservices architectures.
Serverless computing is not so good for legacy applications that do not require elasticity, and that are based on monolithic components (not services-oriented). In some cases, it may also be cost-prohibitive, or there may be specific security or compliance issues to be considered.
When serverless functions are offered as a service by a public cloud provider they are often known as Functions as a Service (FaaS). The two most well-known offerings are AWS Lambda and Azure Functions.
AWS Lambda
AWS Lambda was one of the first serverless computing offerings in the public cloud space and has the largest user base today. Lambda natively supports Java, Go, PowerShell, Node.js, C#, Python, and Ruby code, and provides a Runtime API which allows you to use any additional programming languages to author your functions.
Each AWS Lambda function runs in its own isolated environment, with its own resources and file system view. Code is stored in Amazon S3 and is encrypted at rest. Though there is a default safety throttle for concurrently executing functions, you can in theory scale to any level.
Lambda executes in response to triggers from an event source. An event source is an AWS service or developer-created application that produces events that trigger an AWS Lambda function to run. For example, S3 can trigger Lambda to execute a function when an object is uploaded to an S3 bucket.
The image below depicts an object being uploaded to Amazon S3, which triggers a Lambda function to resize the images into various sizes for different devices, and then store the results:
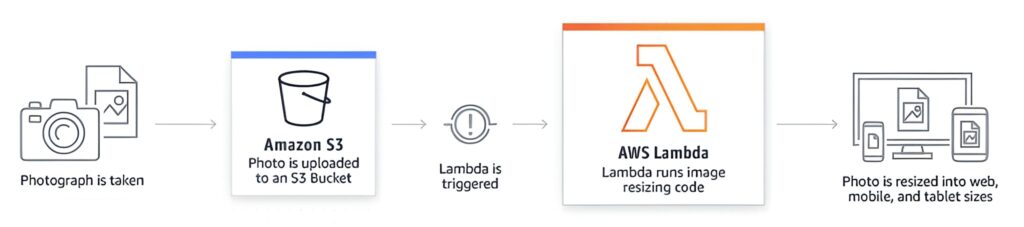
As mentioned previously, serverless functions are not the only form of serverless computing, AWS (and other providers) offer other managed services that deliver computing services without the need for the consumer to manage the underlying operating system. These include (amongst others):
- AWS Fargate (containers)
- Amazon Simple Storage Service (S3)
- Amazon DynamoDB (NoSQL DB)
- Amazon API Gateway
Azure Functions
Azure Functions has a smaller user base than AWS Lambda but is still the second most well known (and used) public cloud serverless computing offering. Azure Functions is tightly coupled with the Azure platform and has many of the same features as AWS Lambda. For companies using Microsoft development approaches Azure Functions may be the obvious choice.
As with AWS Lambda, several programming languages are supported including C#, JavaScript, F#, Java, and Python. Azure Functions also executes based on events created via sources including HTTP, scheduled timers, Azure Cosmos DB, Blobs, and Queues.
The image below depicts an object being added to Blob storage and triggering a function to process it and send the contents of the file for OCR detection and eventual storage of the results in a SQL DB:
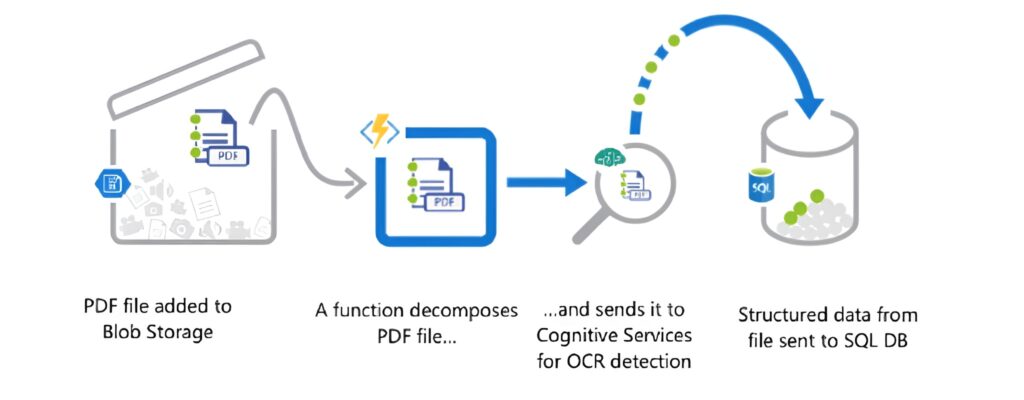
More information
For further information on serverless computing please refer to the following resources:
This article is part of a series, please also check out:
- What is Cloud Computing? Cloud vs Legacy IT
- Cloud Computing Service Models – IaaS, PaaS, SaaS
- Cloud Computing Deployment Models – Public, Private & Hybrid
- Cloud Computing Basics – Compute
- Cloud Computing Basics – Storage
- Cloud Computing Basics – Network
- Cloud Computing Basics – Serverless
Ready to Take Your Tech Career to the Next Level?
- On-Demand Training: Learn at your own pace and on your own schedule.
- Challenge Labs: Apply what you’ve learned in a real-world setting without the risk of incurring surprise cloud bills.
- Cloud Mastery Bootcamp: Build job-ready skills with this live, immersive training that can get you certified faster than you thought possible.