
This AWS storage service is correctly called Amazon S3, but most people search for AWS S3 hence the title. There are a number of storage services in AWS and each of these services are reserved for different use cases.
In order to understand more about Amazon S3, you have to understand what is meant by object storage, and how it compares to file and block level storage.
What is Object storage?
Object storage is a computer data storage architecture that manages data as objects, as opposed to other more hierarchical storage architectures like file systems. Objects are indivisible and immutable meaning that if you want to change the file, you upload a whole other version – this is different to block storage in which a storage file is segmented into blocks, and changes in the file will only affect individual blocks and not the file as a whole.
Amazon Simple Storage Service (Amazon S3) is AWS’s proprietary object-level storage solution, which can store a near unlimited number of objects for any use case imaginable. It is an extremely scalable, durable and reliable service which you can use to manage your AWS infrastructure. S3 has many different use cases from managing log data, handling big data analytics to hosting a static website.
The basic units in S3 are buckets and objects, which are basically folders and files. This configuration, alongside integration with a number of other S3 services can allow fine-grained access to your S3 resources, and allow you to build complex and highly scalable solutions in the AWS cloud.
Different Storage Classes in Amazon S3
There are many different ways you can store your data in S3, each with particular use cases, positives and drawbacks. They are as follows;
- S3 Standard
- Standard IA
- S3 One-Zone IA
- S3 Intelligent Tiering
- S3 Reduced Redundancy Storage
- S3 Glacier / Glacier Deep Archive
I will be discussing the Durability and Availability of each of the classes, which must be understood if you want to get to grips with S3. They can be defined by the following criteria:
- Durability – How likely data is due to be lost due to hardware failure.
- Availability – The data is there to retrieve when you request it.
Let’s start with the S3 Standard class.
S3 Standard Class
The default storage class when uploading data to Amazon S3 is S3 Standard. This is also the most expensive class, but it does have certain properties which make it suitable for certain use cases.
Amazon S3 has an Availability of 99.9% for a given year, and the durability is much more impressive. This is known as the famous ’11 Nines’ of Durability (99.999999999%). This means that if you store 10,000,000 objects on S3 Standard, you can on average expect to incur a loss of a single object once every 10,000 years, which is quite frankly amazing. This is achieved due to the fact that S3 often holds up to 6 copies of your data at any time.
So what can you use S3 standard for? Use cases include:
- Cloud applications
- Content distribution
- Mobile and gaming applications
- Big data analytics
As I said, S3 Standard is the Storage Class where your data is uploaded to automatically, and it gives you a great level of durability and availability as your data is immediately available when you request it. The only downside for this class is the cost, so now we will dive into some cheaper and more interesting classes in S3.
Amazon S3 Standard IA Storage Class
Amazon S3 Standard IA (Infrequent Access) is very similar to the Standard Storage class, with the same level of availability and durability and the same high throughput and low latency as S3 Standard, but with a few added caveats. The data is available immediately when requested, but you have to pay a small retrieval fee, making it perfect for data that is accessed infrequently but is needed immediately when it is requested.
Amazon S3 Standard IA is ideally suited for the following use cases:
- Long-term storage that is required quickly when requested
- Backups
- Data store for disaster recovery files
Amazon S3 One-Zone IA Storage Class
Amazon S3 One Zone IA is extremely similar to Standard IA, as it obviously also is geared towards storing data in a way that is reduced in price, but has an immediate retrieval if necessary. However the difference is in the ‘One-Zone’ it refers to in its name.
One-Zone simply refers to the fact that the data is stored in one Availability zone as opposed to multiple Availability zones in S3 standard. This reduction down to one Availability Zone obviously has its drawbacks in terms of durability of data, so it’s worth noting that if you are going to use One-Zone IA, you may loose the data if a whole AZ goes down!
The reason why some customers are attracted to this however, is that they can store infrequently accessed data within a single Availability Zone at 20% lower cost than S3 Standard-IA whilst still having readily accessible data.
Amazon S3 Intelligent Tiering (my personal favorite Storage Class)
Amazon S3 Intelligent Tiering is one of the newest additions to the range of S3 storage classes, and it is designed to give you the perfect balance between availability, durability and cost optimization.
Intelligent Tiering deduces which class your data should belong in based on how access patterns change over time. Intelligent Tiering works by having your data spread across two (optionally four) tiers. The first two are low latency access tiers optimized for frequent and infrequent access, and the two optional tiers are used for archival purposes
The data is automatically put into the Frequent access tier as soon as the object is uploaded. If the object isn’t accessed in 30 days it will move into the infrequent access tier. If you opt into the archival tiers, your data will drop down into the first archival tier after 90 days without retrieval, and 180 days respectively for the second deep-archival class.
The reduced operational overhead, and the managed tiering this class provides make this tier ideal for use cases with unknown data access patterns (e.g. new apps, data lakes etc).
Amazon S3 Reduced Redundancy Storage Class (legacy)
Amazon S3 Reduced Redundancy (or RRS) is a service that can help some customers solve their unique requirements. Compared to S3 Standard’s mammoth 11 9’s of Durability, RRS boasts a modest 99.99% — which it turns out, is actually more than fine for most use cases. Your data is still stored on multiple devices across multiple locations, but doesn’t have the same durability as S3 Standard. This is actually a legacy storage class and is being deprecated.
Some use cases include:
- Thumbnails
- Transcoded Media
- Less critical data
Amazon S3 Glacier Storage Class
Finally, the last two storage classes are the archival classes in Amazon S3, namely Amazon S3 Glacier and Amazon S3 Glacier Deep Archive.
Amazon S3 Glacier is widely used as a secure and highly durable option to store long term, archival data in an extremely cost-effective manner in Glacier Vaults. The downside to this cheap archival solutions however is that as a standard it can take between minutes and hours to retrieve stored data depending on your selected retrieval option.
Retrieval times are:
- Standard Retrieval can take between 3–5 hours.
- Bulk Retrievals are a petabyte scale retrieval option that retrieves data in between 5–12 hours.
- Expedited Retrieval can allow you to quickly access your data if needed, and they are commonly retrieved in between 1–5 minutes.
Amazon S3 Glacier is widely used for storing data that must be kept for compliance reasons, that rarely if ever needs to be accessed, whilst ensuring that it is there if you do need it.
Amazon S3 Glacier Deep Archive takes it to another level again with even cheaper storage, with the added drawback of taking much longer to retrieve the data.
Amazon S3 Glacier Deep Archive supports digital preservation and long term retention of data that is accessed very rarely. This is used by those often in highly-regulated industries where they need to retain data sets for long periods (7–10 years sometimes!). The retrieval time for Deep Archive is within 12 hours.
Security on S3
It’s important to use the utilities and best practices for securing access to your data on S3. Security guidelines that are put in place to make sure that your data is safe when you are using S3 include:
Blocking All Public Access on an S3 Bucket
By default, when you upload an item to an S3 bucket it is completely private and there is no access to your object from the internet.
This is an extremely important security feature because you have to actively untick multiple boxes in the AWS Management Console to allow any kind of public access. See the image below to put this into context.

Bucket Policies
Bucket Policies are similar to IAM roles, in that you can write bucket policies in JSON to give access to the bucket. The following example policy grants the s3:GetObject permission to any public anonymous users.

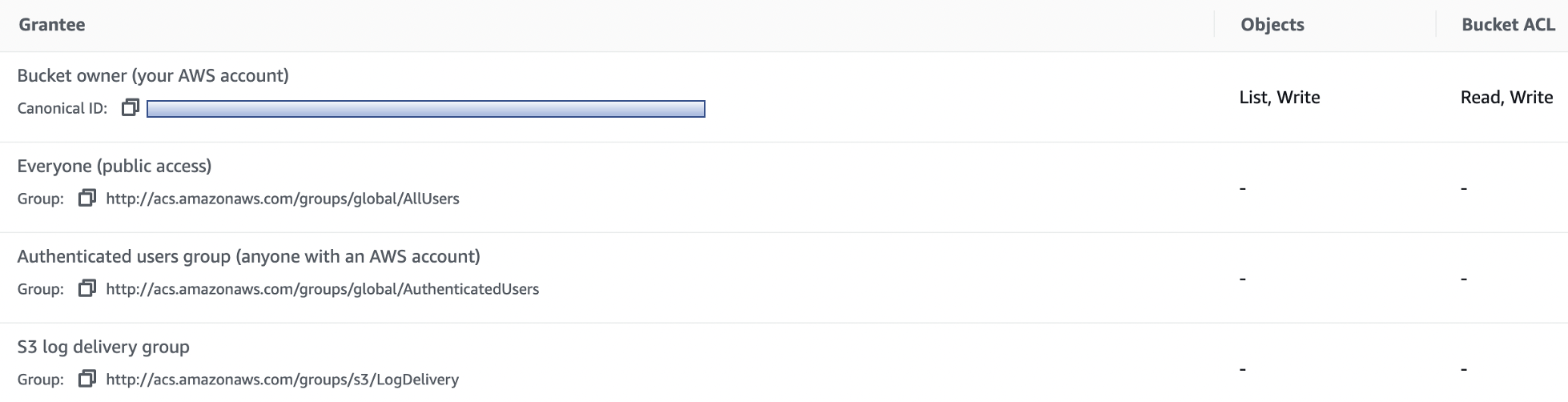
Access Control Lists (ACLs)
Amazon S3 access control lists (ACLs) enable you to manage access to buckets and objects. Each bucket and object has an ACL attached to it as a sub resource. It defines which AWS accounts or groups are granted access and the type of access. When a request is received against a resource, Amazon S3 checks the corresponding ACL to verify that the requester has the necessary access permissions.
When you create a bucket or an object, Amazon S3 creates a default ACL that grants the resource owner full control over the resource.
Object Lock
S3 Object Lock blocks object version deletion during a retention period that you define, so that you can enforce retention policies as an added layer of data protection or if you need to enforce regulatory compliance.
Object lock implements something called the WORM model, also known as Write Once, Read Many meaning that your object cannot be edited, but can be read as many times as needed.
Encryption in transit / at rest
Amazon S3 supports both server-side encryption (with three key management options: SSE-KMS, SSE-C, SSE-S3) and client-side encryption for data uploads. Amazon S3 offers flexible security features to block unauthorized users from accessing your data.
You also need to ensure that you are (when possible) using other AWS services like VPC Gateway Endpoints, AWS Trusted Advisor, Amazon Macie etc. to further bolster your security posture on AWS.
Get Hands-On with AWS S3!
Check out this AWS Lambda tutorial to learn how to create a simple AWS S3 bucket.
Get hands-on with AWS Lambda challenge labs in a secure sandbox environment to build your job-ready skills.