
AWS Glue is a pay-as-you-go service from Amazon that helps you with your ETL (extract, transform and load) needs. It automates time-consuming steps of data preparation for analytics. It extracts the data from different data sources, transforms it, and then saves it in the data warehouse. Today, we will explore AWS Glue in detail. Let’s start with the components of AWS Glue.
AWS Glue Components
Below, you’ll find some of the core components of AWS Glue.
Data Catalog
Data Catalog is the persistent metadata store in your AWS Glue. You have one data catalog per AWS account. It contains the metadata related to all your data sources, table definitions, and job definitions to manage the ETL process in AWS Glue.
Crawler
Crawler connects to your data source and data targets. It crawls through the schema and creates metadata in your AWS Glue data catalog.
Classifier
The classifier object determines the schema of a data store. AWS Glue has built-in classifiers for common data types like CSV, Json, XML, etc. AWS Glue also provides default classifiers for common RDBMS systems as well.
Data store
A data store is used to store the actual data in a persistent data storage system like S3 or a relational database management system.
Database
Database in the AWS Glue terminology refers to the collection of associated data catalog table definitions organized into a logical group in AWS Glue.
AWS Glue Architecture
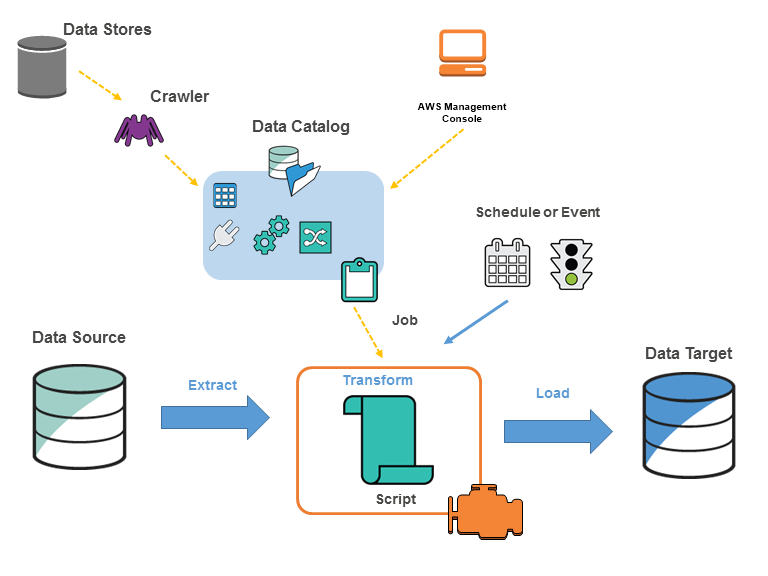
How AWS Glue Works
- You will Identify the data sources which you will use.
- You will define a crawler to point to each data source and populate the AWS Glue data catalog with the metadata table definitions. This metadata will be used when data is transformed during the ETL process.
- Now your data catalog has been categorized, and the data is available for instant searching, querying, and ETL processing.
- You will provide a script through the console or API so that the data can be transformed. AWS Glue can also generate a script for this purpose.
- You will run the job or schedule the job to run based on a particular trigger. A trigger can be based on a particular schedule or occurring of an event.
- When a job is executed, the script extracts the data from the data source(s), transforms it, and loads the transformed data into the data target. The script is run in the Apache Spark environment in AWS Glue.
When To Use AWS Glue
Below are some of the top use cases for AWS Glue.
Build a data warehouse
If you want to build a data warehouse that will collect data from different sources, cleanse it, validate it, and transform it, then AWS Glue is an ideal fit. You can transform and move the AWS cloud data into your data store too.
Use AWS S3 as data lake
You can convert your S3 data into a data lake by cataloguing its data into AWS Glue. The transformed data will be available to AWS redshift and AWS Athena for querying. Both Redshift and Athena can directly query your S3 using AWS Glue.
Create event-driven ETL pipeline
AWS Glue is a perfect fit if you want to launch an ETL job as soon as fresh data is available in S3. You can use AWS Lambda along with AWS Glue to orchestrate the ETL process.
Features of AWS Glue
Below are some of the top features of AWS Glue.
Automatic schema recognition
Crawler is a very powerful component of AWS Glue that automatically recognizes the schema of your data. Users do not need to design the schema of each data source manually. Crawlers automatically identify the schema and parse the data.
Automatic ETL code generation
AWS Glue is capable of creating the ETL code automatically. You just need to specify the source of the data and its target data store; AWS Glue will automatically create the relevant code in scala or python for the entire ETL pipeline.
Job scheduler
ETL jobs are very flexible in AWS Glue. You can execute the jobs on-demand, and you can also schedule them to be triggered based on a schedule or event. Multiple jobs can be executed in parallel, and you can even mention the job dependencies as well.
Developer endpoints
Developers can take advantage of developer endpoints to debug AWS Glue as well as develop custom crawlers, writers, and data transformers, which can later be imported into custom libraries.
Integrated data catalog
The data catalog is the most powerful component of AWS Glue. It is the central metadata store of all the diverse data sources of your pipeline. You only have to maintain just one data catalog per AWS account.
Benefits of Using AWS Glue
Strong integrations
AWS Glue has strong integrations with other AWS services. It provides native support for AWS RDS and Aurora databases. It also supports AWS Redshift, S3, and all common database engines and databases running in your EC2 instances. AWS Glue even supports NoSQL data sources like DynamoDB.
Built-in orchestration
You do not need to set up or maintain ETL pipeline infrastructure. AWS Glue will automatically handle the low-level complexities for you. The crawlers automate the process of schema identification and parsing, freeing you from the burden of manually evaluating and parsing different complex data sources. AWS Glue also creates the ETL pipeline code automatically. It has built-in features for logging, monitoring, alerting, and restarting failure scenarios as well.
AWS Glue is serverless, which means you do not need to worry about maintaining the underlying infrastructure. AWS glue has built-in scaling capabilities, so it can automatically handle the extra load. It automatically handles the setup, configuration, and scaling of underlying resources.
Cost-effective
You only pay for what you use. You will only be charged for the time when your jobs are running. This is especially beneficial if your workload is unpredictable and you are not sure about the infrastructure to provision for your ETL jobs.
Drawbacks of Using AWS Glue
Here are some of the drawbacks of using AWS Glue.
Reliance on Apache Spark
As the AWS Glue jobs run in Apache Spark, the team must have expertise in Spark in order to customize the generated ETL job. AWS Glue also creates the code in python or scala – so your engineers must have knowledge of these programming languages too.
Complexity of some use cases
Apache spark is not very efficient in use cases like advertisement, gaming, and fraud detection because these jobs need high cardinality joins. Spark is not very good when it comes to high cardinality joins. You can handle these scenarios by implementing additional components, although that will make your ETL pipeline complex.
Similarly, if you need to combine steam and batch jobs, that will be complex to handle in AWS Glue. This is because AWS Glue requires batch and stream processes to be separate. As a result, you need to maintain extra code to make sure that both of these processes run in a combined manner.
AWS Glue Pricing
For the ETL jobs, you will be charged only for the time the job is running. AWS will charge you on an hourly basis depending on the number of DPUs (Data Processing Units) that are needed to run your job. One DPU is approximately 4 vCPUs with 16GB of memory. You will also pay for the storage of the data stored in the AWS Glue data catalog. The first million objects are free in the catalog, and the first million accesses are also free. Crawlers and development endpoints are also charged based on an hourly rate, and the rate depends on the number of DPU’s.
Frequently Asked Questions
How is AWS Glue different from AWS Lake Formation?
Lake Formation’s main area is governance and data management functionality, whereas AWS Glue is strong in ETL and data processing. They both complement each other as the lake formation is primarily a permission management layer that uses the AWS glue catalog under the hood.
Can AWS Glue write to DynamoDB?
Yes, AWS Glue can write to DynamoDB. However, the option of writing is not available in the console. You will need to customize the script to achieve that.
Can AWS Glue write to RDS?
Yes, AWS Glue can write to any RDS engine. When using the ETL job wizard, you can select the target option of “JDBC” and then you can create a connection to any RDS-compliant database.
Is AWS Glue in real-time?
AWS Glue can process data from Amazon Kinesis Data Streams using micro-batches in real-time. For a large data set, there might be some delay. It can process petabytes of data both in batches and in real-time.
Does AWS Glue Auto Scale?
AWS Glue provides autoscaling starting from version 3.0. It automatically adds or removes workers based on the workload.
Where is AWS Glue Data Catalog Stored?
As AWS Glue is a drop-in replacement to Hive metastore. Most probably, the data is stored in MySQL database. However, it is not confirmed because there is no official information from AWS regarding this.
How Fast is AWS Glue?
AWS Glue 3 has improved a lot in terms of speed. The speed of version 3 is 2.4 times faster than the version 2. This is because it uses vectorized readers and micro-parallel SIMD CPU instructions for faster data parsing, tokenization, and indexing.
Is AWS Glue Expensive?
No, AWS Glue is not expensive. This is because it is based on serverless architecture, and you are charged only when it is actually used. There is no permanent infrastructure cost, so AWS Glue is not costly.
Is AWS Glue a Database?
No. AWS Glue is a fully managed cloud service from Amazon through which you can prepare data for analysis through an automated ETL process.
Is AWS Glue difficult to learn?
AWS Glue is not really difficult to learn. This is because it provides a GUI-based interface through which you can easily manage the process of authoring, running, and monitoring the whole process of ETL jobs.
What is The Difference Between AWS Glue and EMR?
AWS Glue and EMR are both AWS solutions for ETL processing. EMR is a slightly faster and cheaper platform, especially if you already have the required infrastructure available. However, if you want a serverless solution where you expect your workload to be inconsistent, then AWS Glue is the better option.
Conclusion
AWS Glue is a powerful and fully managed service for your ETL needs. AWS Glue automates a lot of tasks related to data analysis, conversion, metadata, etc. You save time and cost by using AWS Glue, and it provides extensive integrations with other services too.
Get AWS Certified
Becoming AWS certified is the best way to deepen your understanding of AWS services. Enroll in our popular AWS training courses to develop the skills and knowledge needed to implement different AWS services, including AWS Glue.
Learn how to Master the Cloud
AWS Training – Our popular AWS training will maximize your chances of passing your AWS certification the first time.
Membership – For unlimited access to our entire cloud training catalog, enroll in our monthly or annual membership program.
Challenge Labs – Build hands-on cloud skills in a secure sandbox environment. Learn, build, test and fail forward without risking unexpected cloud bills.