
Within the AWS Cloud there are various service options for many different types of architectures. With regard to the different AWS storage types of services, this cheat sheet will give you an in-depth overview on how to decide which of the AWS storage options to choose from, and which of the AWS storage services is ideal for any particular use case.
While it may seem challenging to choose the right AWS storage service from the list of AWS storage services, this cheat sheet will make this task manageable as it provides a succinct comparison of each AWS storage services.
This article will also discuss AWS Compute in the context of the AWS Certified Cloud Practitioner Exam. Keep in mind that AWS Compute is one of the key technology areas covered in the exam guide.
Amazon Simple Storage Service (S3)
Amazon S3 is object storage built to store and retrieve any amount of data from anywhere – web sites and mobile apps, corporate applications, and data from IoT sensors or devices.
You can store any type of file in S3.
S3 is designed to deliver 99.999999999% durability, and stores data for millions of applications used by market leaders in every industry.
S3 provides comprehensive security and compliance capabilities that meet even the most stringent regulatory requirements.
S3 gives customers flexibility in the way they manage data for cost optimization, access control, and compliance.
Typical use cases include:
- Backup and Storage – Provide data backup and storage services for others.
- Application Hosting – Provide services that deploy, install, and manage web applications.
- Media Hosting – Build a redundant, scalable, and highly available infrastructure that hosts video, photo, or music uploads and downloads.
- Software Delivery – Host your software applications that customers can download.
- Static Website – you can configure a static website to run from an S3 bucket.
S3 provides query-in-place functionality, allowing you to run powerful analytics directly on your data at rest in S3. And Amazon S3 is the most supported cloud storage service available, with integration from the largest community of third-party solutions, systems integrator partners, and other AWS services.
Files can be anywhere from 0 bytes to 5 TB.
There is unlimited storage available.
Files are stored in buckets.
Buckets are root level folders.
Any subfolder within a bucket is known as a “folder”.
S3 is a universal namespace so bucket names must be unique globally.
There are seven S3 storage classes.
- S3 Standard (durable, immediately available, frequently accessed).
- S3 Intelligent-Tiering (automatically moves data to the most cost-effective tier).
- S3 Standard-IA (durable, immediately available, infrequently accessed).
- S3 One Zone-IA (lower cost for infrequently accessed data with less resilience).
- S3 Glacier Instant Retrieval (data that is rarely accessed and requires retrieval in milliseconds).
- S3 Glacier Flexible Retrieval (archived data, retrieval times in minutes or hours).
- S3 Glacier Deep Archive (lowest cost storage class for long term retention).
The table below provides the details of each Amazon S3 storage class:
| S3 Standard | S3 Intelligent Tiering | S3 Standard-IA | S3 One Zone-IA | S3 Glacier Instant Retrieval | S3 Glacier Flexible Retrieval | S3 Glacier Deep Archive | |
| Designed for durability | 11 9s | 11 9s | 11 9s | 11 9s | 11 9s | 11 9s | 11 9s |
| Designed for availability | 99.99% | 99.9& | 99.9% | 99.5% | 99.9% | 99.99% | 99.99% |
| Availability SLA | 99.9% | 99% | 99% | 99% | 99% | 99.99% | 99.9% |
| Availability Zones | ≥3 | ≥3 | ≥3 | 1 | ≥3 | ≥3 | ≥3 |
| Minimum capacity charge per object | N/A | N/A | 128KB | 128KB | 128KB | 40KB | 40KB |
| Minimum storage duration charge | N/A | N/A | 30 days | 30 days | 90 days | 90 days | 180 days |
| Retrieval fee | N/A | N/A | Per GB retrieved | Per GB retrieved | Per GB retrieved | Per GB retrieved | Per GB retrieved |
| First byte latency | milliseconds | milliseconds | milliseconds | milliseconds | milliseconds | minutes or hours | hours |
When you successfully upload a file to S3 you receive a HTTP 200 code.
S3 is a persistent, highly durable data store.
Persistent data stores are non-volatile storage systems that retain data when powered off.
This contrasts with transient data stores and ephemeral data stores which lose the data when powered off.
The following table provides a description of persistent, transient, and ephemeral data stores and which AWS service to use:
| Storage Type | Description | Examples |
| Persistent Data Store | Data is durable and sticks around after reboots, restarts, or power cycles | S3, Glacier, EBS, EFS |
| Transient Data Store | Data is just temporarily stored and passed along to another process or persistent store | SQS, SNS |
| Ephemeral Data Store | Data is lost when the system is stopped | EC2 Instance Store, Memcached |
Bucket names must follow a set of rules:
- Names must be unique across all of AWS.
- Names must be 3 to 63 characters in length.
- Names can only contain lowercase letters, numbers, and hyphens.
- Names cannot be formatted as an IP address.
Objects consist of:
- Key (name of the object).
- Value (data made up of a sequence of bytes).
- Version ID (used for versioning).
- Metadata (data about the data that is stored).
Subresources:
- Access control lists.
- Torrent.
Object sharing – the ability to make any object publicly available via a URL.
Lifecycle management – set rules to transfer objects between storage classes at defined time intervals.
Versioning – automatically keep multiple versions of an object (when enabled).
Encryption can be enabled for bucket.
Data is secured using ACLs and bucket policies.
Charges:
- Storage.
- Requests.
- Storage management pricing.
- Data transfer pricing.
- Transfer acceleration.
When you create a bucket you need to select the region where it will be created.
It is a best practice to create buckets in regions that are physically closest to your users to reduce latency.
Additional capabilities offered by Amazon S3 include:
| Additional S3 Capability | How it Works |
| Transfer Acceleration | Speed up data uploads using CloudFront in reverse |
| Requester Pays | The requester rather than the bucket owner pays for requests and data transfer |
| Tags | Assign tags to objects to use in costing, billing, security etc. |
| Events | Trigger notifications to SNS, SQS, or Lambda when certain events happen in your bucket |
| Static Web Hosting | Simple and massively scalable static website hosting |
| BitTorrent | Use the BitTorrent protocol to retrieve any publicly available object by automatically generating a .torrent file |
AWS Snowball
With AWS Snowball (Snowball), you can transfer hundreds of terabytes or petabytes of data between your on-premises data centers and Amazon Simple Storage Service (Amazon S3).
Uses a secure storage device for physical transportation.
AWS Snowball Client is software that is installed on a local computer and is used to identify, compress, encrypt, and transfer data.
Uses 256-bit encryption (managed with the AWS KMS) and tamper-resistant enclosures with TPM.
The table below describes the AWS Snow offerings at a high-level:
| Service | What it Is |
| AWS Snowball | Bulk data transfer, edge storage, and edge compute |
| AWS Snowmobile | A literal shipping container full of storage (up to 100PB) and a truck to transport it |
| AWS Snowcone | The smallest device in the range that is best suited for outside the data center |
Snowball can import to S3 or export from S3.
Import/export is when you send your own disks into AWS – this is being deprecated in favor of Snowball.
Snowball must be ordered from and returned to the same region.
To speed up data transfer it is recommended to run simultaneous instances of the AWS Snowball Client in multiple terminals and transfer small files as batches.
Amazon Elastic Block Store (EBS)
Amazon Elastic Block Store (Amazon EBS) provides persistent block storage volumes for use with Amazon EC2 instances in the AWS Cloud.
Each Amazon EBS volume is automatically replicated within its Availability Zone to protect you from component failure, offering high availability and durability.
Amazon EBS volumes offer the consistent and low-latency performance needed to run your workloads. With Amazon EBS, you can scale your usage up or down within minutes – all while paying a low price for only what you provision.
The following EBS volumes appear most often on the AWS exams:
EBS volume data persists independently of the life of the instance.
EBS volumes do not need to be attached to an instance.
You can attach multiple EBS volumes to an instance.
You cannot attach an EBS volume to multiple instances (use Elastic File Store instead).
EBS volumes must be in the same AZ as the instances they are attached to.
Termination protection is turned off by default and must be manually enabled (keeps the volume/data when the instance is terminated).
Root EBS volumes are deleted on termination by default.
Extra non-boot volumes are not deleted on termination by default.
The behavior can be changed by altering the “DeleteOnTermination” attribute.
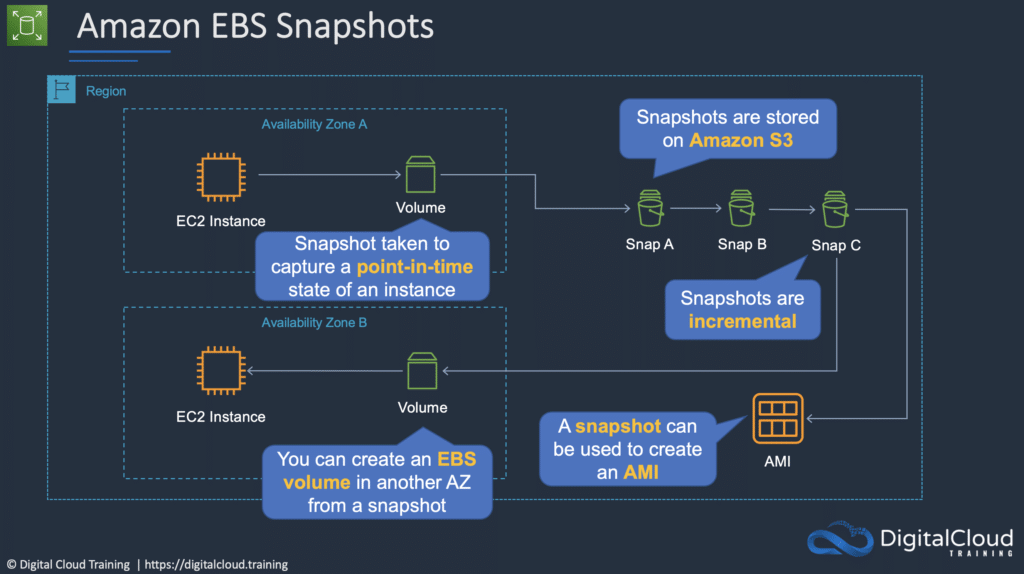
EBS Snapshots:
- Snapshots capture a point-in-time state of an instance.
- Snapshots are stored on S3.
- Does not provide granular backup (not a replacement for backup software).
- If you make periodic snapshots of a volume, the snapshots are incremental, which means that only the blocks on the device that have changed after your last snapshot are saved in the new snapshot.
- Even though snapshots are saved incrementally, the snapshot deletion process is designed so that you need to retain only the most recent snapshot to restore the volume.
- Snapshots can only be accessed through the EC2 APIs.
- EBS volumes are AZ specific, but snapshots are region specific.
Instance Store Volumes
Instance store volumes are high performance local disks that are physically attached to the host computer on which an EC2 instance runs.
Instance stores are ephemeral which means the data is lost when powered off (non-persistent).
Instances stores are ideal for temporary storage of information that changes frequently, such as buffers, caches, or scratch data.
Instance store volume root devices are created from AMI templates stored on S3.
Instance store volumes cannot be detached/reattached.
Amazon Elastic File System (EFS)
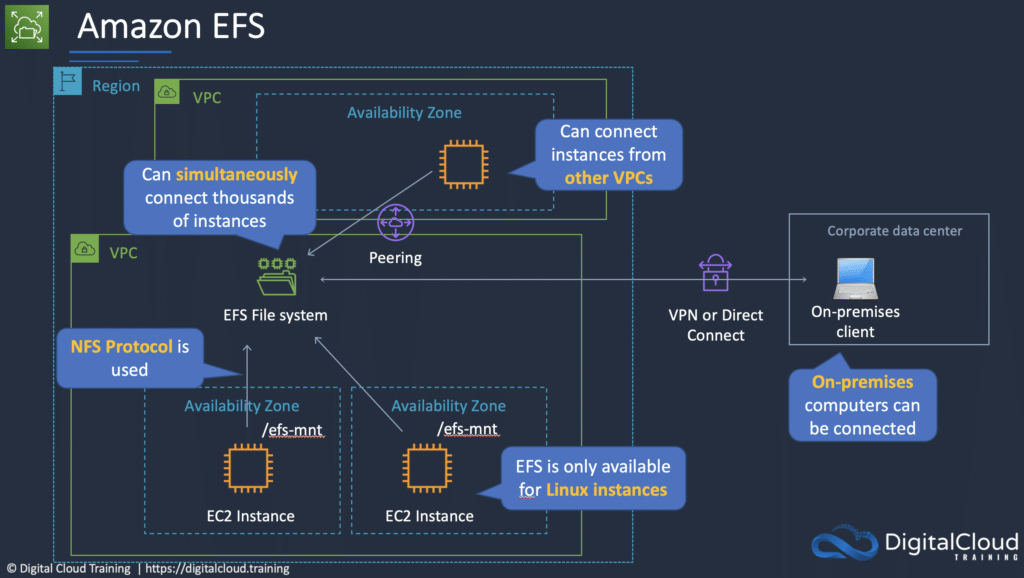
EFS is a fully managed service that makes it easy to set up and scale file storage in the Amazon Cloud.
Good for big data and analytics, media processing workflows, content management, web serving, home directories etc.
EFS uses the NFS protocol.
Pay for what you use (no pre-provisioning required).
Can scale up to petabytes.
EFS is elastic and grows and shrinks as you add and remove data.
Can concurrently connect 1 to 1000s of EC2 instances, from multiple AZs.
A file system can be accessed concurrently from all AZs in the region where it is located.
By default you can create up to 10 file systems per account.
On-premises access can be enabled via Direct Connect or AWS VPN.
Can choose General Purpose or Max I/O (both SSD).
The VPC of the connecting instance must have DNS hostnames enabled.
EFS provides a file system interface, file system access semantics (such as strong consistency and file locking).
Data is stored across multiple AZs within a region.
Read after write consistency.
Need to create mount targets and choose AZs to include (recommended to include all AZ’s).
Instances can be behind an ELB.
There are two performance modes:
- “General Purpose” performance mode is appropriate for most file systems.
- “Max I/O” performance mode is optimized for applications where tens, hundreds, or thousands of EC2 instances are accessing the file system.
Amazon EFS is designed to burst to allow high throughput levels for periods of time.
AWS Storage Gateway
AWS Storage Gateway is a hybrid cloud storage service that gives you on-premises access to virtually unlimited cloud storage.
Customers use Storage Gateway to simplify storage management and reduce costs for key hybrid cloud storage use cases.
These include moving backups to the cloud, using on-premises file shares backed by cloud storage, and providing low latency access to data in AWS for on-premises applications.
To support these use cases, Storage Gateway offers three different types of gateways:
- File Gateway – provides file system interfaces to on-premises servers.
- Volume Gateway – provides block-based access for on-premises servers.
- Tape Gateway – provides a virtual tape library that is compatible with common backup software (block and file interfaces).
AWS Backup
The AWS Backup service offers a centralized backup console, APIs, and command line interface for managing backups across AWS services, including:
- Amazon Simple Storage Service (S3)
- Amazon Elastic Block Store (EBS)
- Amazon FSx
- Amazon Elastic Compute Cloud (EC2)
- Amazon Relational Database Service (RDS)
- Amazon DynamoDB
- Amazon Elastic File System (EFS)
- AWS Storage Gateway
- … and more
AWS Backup allows you to centrally manage backup policies that meet your backup requirements and apply them across your AWS resources across AWS services as well as hybrid cloud workloads. This enables you to back up your application data consistently and in accordance with compliance requirements. Moreover, AWS Backup’s centralized backup console offers a consolidated view of your backups and backup activity logs, making it easier to audit your backups.
Amazon FSX for Lustre
For compute workloads, Amazon FSx for Lustre provides scalable, high-performance, cost-effective storage for compute workloads. Based on Lustre, the world’s most popular high-performance file system, FSx for Lustre provides shared storage with sub-ms latencies, up to terabytes of throughput, and millions of IOPS. It is also possible to link FSx for Lustre file systems to Amazon Simple Storage Service (S3) buckets, allowing you to access and process data simultaneously from both.
A number of the fastest computers in the world use the Lustre open source file system to process ever-growing data sets quickly and cheaply. It is suitable for workloads ranging from genome sequencing to video transcoding to machine learning to fraud detection. Lustre has been battle-tested across a wide range of industries – from energy to life sciences to media production to financial services.
Amazon FSX for Windows File Server
Your applications and end users can access reliable, performant, and secure shared file storage with Amazon FSx for Windows File Server. Using Amazon FSx, you can create highly available and durable file systems that span multiple availability zones (AZs) and can be accessed from up to thousands of computing instances.
In addition to providing a rich set of administrative and security features, it also integrates with Microsoft Active Directory (AD). For a variety of workloads, Amazon FSx provides high levels of file system throughput and IOPS as well as consistent sub-millisecond latencies.
Based on Windows Server, Amazon FSx includes a rich set of administrative features, including end-user file restore, user quotas, and access control lists (ACLs). Windows Server supports the SMB protocol natively, allowing Windows-based applications to access shared file storage. SMB file shares can also be accessed from Linux and MacOS, so any application or user can access the storage. AWS Microsoft Managed AD and your on-premises Microsoft Active Directory can be integrated with Amazon FSx to control user access.