

AWS Lambda
Please use the menu below to navigate the article sections:
- Invoking Lambda Functions
- Event source mappings
- Lambda Versions
- Lambda Aliases
- Traffic Shifting
- Lambda Handler
- Function Dependencies
- Concurrent executions
- Lambda Layers
- Lambda@Edge
- Lambda and Amazon VPC
- Building Lambda Apps
- Elastic Load Balancing
- Lambda Limits
- Operations and Monitoring
- Development Best Practices
- Charges

AWS Lambda lets you run code as functions without provisioning or managing servers.
Lambda-based applications are composed of functions triggered by events.
With serverless computing, your application still runs on servers, but all the server management is done by AWS.
You cannot log in to the compute instances that run Lambda functions or customize the operating system or language runtime.
Lambda functions:
- Consist of code and any associated dependencies.
- Configuration information is associated with the function.
- You specify the configuration information when you create the function.
- API provided for updating configuration data.
You specify the amount of memory you need allocated to your Lambda functions.
AWS Lambda allocates CPU power proportional to the memory you specify using the same ratio as a general purpose EC2 instance type.
Functions can access:
- AWS services or non-AWS services.
- AWS services running in VPCs (e.g. RedShift, Elasticache, RDS instances).
- Non-AWS services running on EC2 instances in an AWS VPC.
To enable your Lambda function to access resources inside your private VPC, you must provide additional VPC-specific configuration information that includes VPC subnet IDs and security group IDs.
AWS Lambda uses this information to set up elastic network interfaces (ENIs) that enable your function.
You can request additional memory in 1 MB increments from 128 MB to 10240 MB.
There is a maximum execution timeout.
- Max is 15 minutes (900 seconds), default is 3 seconds.
- You pay for the time it runs.
- Lambda terminates the function at the timeout.
Code is invoked using API calls made using AWS SDKs.
Lambda assumes an IAM role when it executes the function.
AWS Lambda stores code in Amazon S3 and encrypts it at rest.
Lambda provides continuous scaling – scales out not up.
Lambda scales concurrently executing functions up to your default limit (1000).
Lambda can scale up to tens of thousands of concurrent executions.
Lambda functions are serverless and independent, 1 event = 1 function.
Functions can trigger other functions so 1 event can trigger multiple functions.
Use cases fall within the following categories:
- Using Lambda functions with AWS services as event sources.
- On-demand Lambda function invocation over HTTPS using Amazon API Gateway (custom REST API and endpoint).
- On-demand Lambda function invocation using custom applications (mobile, web apps, clients) and AWS SDKs, AWS Mobile SDKs, and the AWS Mobile SDK for Android.
- Scheduled events can be configured to run code on a scheduled basis through the AWS Lambda Console.
Invoking Lambda Functions
You can invoke Lambda functions directly with the Lambda console, the Lambda API, the AWS SDK, the AWS CLI, and AWS toolkits.
You can also configure other AWS services to invoke your function, or you can configure Lambda to read from a stream or queue and invoke your function.
When you invoke a function, you can choose to invoke it synchronously or asynchronously.
Other AWS services and resources invoke your function directly.
For example, you can configure CloudWatch Events to invoke your function on a timer, or you can configure Amazon S3 to invoke your function when an object is created.
Each service varies in the method it uses to invoke your function, the structure of the event, and how you configure it.
Synchronous invocation
You wait for the function to process the event and return a response.
When you invoke a function synchronously, Lambda runs the function and waits for a response.
When the function execution ends, Lambda returns the response from the function’s code with additional data, such as the version of the function that was executed. To invoke a function synchronously with the AWS CLI, use the invoke command.
$ aws lambda invoke –function-name my-function –payload ‘{ “key”: “value” }’ response.json { “ExecutedVersion”: “$LATEST”, “StatusCode”: 200 }
Asynchronous invocation
When you invoke a function asynchronously, you don’t wait for a response from the function code.
For asynchronous invocation, Lambda handles retries and can send invocation records to a destination.
For asynchronous invocation, Lambda places the event in a queue and returns a success response without additional information. A separate process reads events from the queue and sends them to your function. To invoke a function asynchronously, set the invocation type parameter to Event.
$ aws lambda invoke --function-name my-function --invocation-type Event --payload '{ "key": "value" }' response.json { "StatusCode": 202 }
The output file (response.json) doesn’t contain any information but is still created when you run this command. If Lambda can’t add the event to the queue, the error message appears in the command output.
Event source mappings
Lambda is an event-driven compute service where AWS Lambda runs code in response to events such as changes to data in an S3 bucket or a DynamoDB table.
An event source is an AWS service or developer-created application that produces events that trigger an AWS Lambda function to run.
You can use event source mappings to process items from a stream or queue in services that don’t invoke Lambda functions directly.
Supported AWS event sources include:
- Amazon S3.
- Amazon DynamoDB.
- Amazon Kinesis Data Streams.
- Amazon Simple Notification Service.
- Amazon Simple Email Service.
- Amazon Simple Queue Service.
- Amazon Cognito.
- AWS CloudFormation.
- Amazon CloudWatch Logs.
- Amazon CloudWatch Events.
- AWS CodeCommit.
- AWS Config.
- Amazon Alexa.
- Amazon Lex.
- Amazon API Gateway.
- AWS IoT Button.
- Amazon CloudFront.
- Amazon Kinesis Data Firehose.
- Other Event Sources: Invoking a Lambda Function On Demand.
Other event sources can invoke Lambda functions on-demand.
Applications need permissions to invoke Lambda functions.
Lambda can run code in response to HTTP requests using Amazon API gateway or API calls made using the AWS SDKs.
Services that Lambda reads events from:
An event source mapping uses permissions in the function’s execution role to read and manage items in the event source.
Permissions, event structure, settings, and polling behavior vary by event source.
To process items from a stream or queue, you can create an event source mapping.
Each event that your function processes can contain hundreds or thousands of items.
The configuration of the event source mapping for stream-based services (DynamoDB, Kinesis), and Amazon SQS, is made on the Lambda side.
Note: for other services such as Amazon S3 and SNS, the function is invoked asynchronously, and the configuration is made on the source (S3/SNS) rather than Lambda.
Lambda Versions
Versioning means you can have multiple versions of your function.
You can use versions to manage the deployment of your AWS Lambda functions. For example, you can publish a new version of a function for beta testing without affecting users of the stable production version.
The function version includes the following information:
- The function code and all associated dependencies.
- The Lambda runtime that executes the function.
- All the function settings, including the environment variables.
- A unique Amazon Resource Name (ARN) to identify this version of the function.
You work on $LATEST which is the latest version of the code – this is mutable (changeable).
When you’re ready to publish a Lambda function you create a version (these are numbered).
Numbered versions are assigned a number starting with 1 and subsequent versions are incremented by 1.
Versions are immutable (code cannot be edited).
Each version has its own ARN.
Because different versions have unique ARNs this allows you to effectively manage them for different environments like Production, Staging or Development.
A qualified ARN has a version suffix.
An unqualified ARN does not have a version suffix.
You cannot create an alias from an unqualified ARN.
Lambda Aliases
Lambda aliases are pointers to a specific Lambda version.
Using an alias you can invoke a function without having to know which version of the function is being referenced.
Aliases are mutable.
Aliases enable stable configuration of event triggers / destinations.
Aliases also have static ARNs but can point to any version of the same function.
Aliases can also be used to split traffic between Lambda versions (blue/green).
Aliases enable blue / green deployment by assigning weights to Lambda version (doesn’t work for $LATEST, you need to create an alias for $LATEST).
Traffic Shifting
With the introduction of alias traffic shifting, it is now possible to trivially implement canary deployments of Lambda functions.
By updating additional version weights on an alias, invocation traffic is routed to the new function versions based on the weight specified.
Detailed CloudWatch metrics for the alias and version can be analyzed during the deployment, or other health checks performed, to ensure that the new version is healthy before proceeding.
The following example AWS CLI command points an alias to a new version, weighted at 5% (original version at 95% of traffic):
aws lambda update-alias --function-name myfunction --name myalias --routing-config '{"AdditionalVersionWeights" : {"2" : 0.05} }'
Lambda Handler
A handler is a function which Lambda will invoke to execute your code – it is an entry point.
When you create a Lambda function, you specify a handler that AWS Lambda can invoke when the service executes the function on your behalf.
You define a Lambda function handler as an instance or static method in a class.
Function Dependencies
If your Lambda function depends on external libraries such as AWS X-Ray SDK, database clients etc. you need to install the packages with the code and zip it all up.
- For Node.js use npm & “node modules” directory.
- For Python use pip — target options.
- For Java include the relevant .jar files.
Upload the zip file straight to Lambda if it’s less than 50MB, otherwise upload to S3.
Native libraries work they need to be compiled on Amazon Linux.
AWS SDK comes with every Lambda function by default.
Concurrent executions
Managing Concurrency
The first time you invoke your function, AWS Lambda creates an instance of the function and runs its handler method to process the event. When the function returns a response, it stays active and waits to process additional events. If you invoke the function again while the first event is being processed, Lambda initializes another instance, and the function processes the two events concurrently.
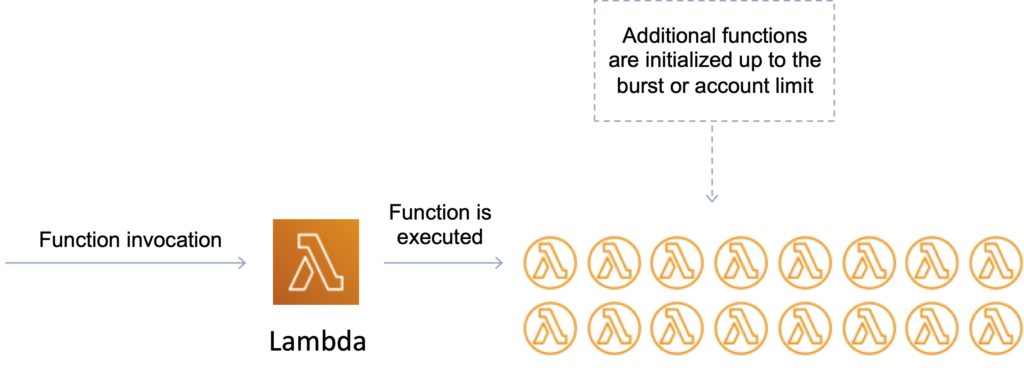
Your functions’ concurrency is the number of instances that serve requests at a given time. For an initial burst of traffic, your functions’ cumulative concurrency in a Region can reach an initial level of between 500 and 3000, which varies per Region.
Burst Concurrency Limits:
- 3000 – US West (Oregon), US East (N. Virginia), Europe (Ireland).
- 1000 – Asia Pacific (Tokyo), Europe (Frankfurt).
- 500 – Other Regions.
After the initial burst, your functions’ concurrency can scale by an additional 500 instances each minute. This continues until there are enough instances to serve all requests, or until a concurrency limit is reached.
The default account limit is up to 1000 executions per second, per region (can be increased).
This is a safety feature to limit the number of concurrent executions across all functions in each region per account.
Each invocation over the concurrency limit will trigger a throttle.
TooManyRequestsExeception may be experienced if the concurrent execution limit is exceeded.
You may receive a HTTP status code: 429 and the message is “Request throughput limit exceeded”.
Throttle behavior:
- For synchronous invocations returns throttle error 429.
- For asynchronous invocations retries automatically (twice) then goes to a Dead Letter Queue (DLQ).
A DLQ can be an SNS topic or SQS queue.
The original event payload is sent to the DLQ.
The Lambda function needs an IAM role with permissions to SNS / SQS.
Lambda also integrates with X-Ray for debugging.
- Can trace Lambda with X-Ray.
- Need to enable in the Lambda configuration and it will run the X-Ray daemon.
- Use AWS SDK in your code.
Reserved Concurrency
You can set a reserved concurrency at the function level to guarantee a set number of concurrent executions will be available for a critical function.
You can reserve up to the Unreserved account concurrency value that is shown in the console, minus 100 for functions that don’t have reserved concurrency.
To throttle a function, set the reserved concurrency to zero. This stops any events from being processed until you remove the limit.
To reserve concurrency for a function
- Open the Lambda console Functions page.
- Choose a function.
- Under Concurrency, choose Reserve concurrency.
- Enter the amount of concurrency to reserve for the function.
- Choose Save.
Provisioned Concurrency
When provisioned concurrency is allocated, the function scales with the same burst behavior as standard concurrency.
After it’s allocated, provisioned concurrency serves incoming requests with very low latency.
When all provisioned concurrency is in use, the function scales up normally to handle any additional requests.
Application Auto Scaling takes this a step further by providing autoscaling for provisioned concurrency.
With Application Auto Scaling, you can create a target tracking scaling policy that adjusts provisioned concurrency levels automatically, based on the utilization metric that Lambda emits.
Use the Application Auto Scaling API to register an alias as a scalable target and create a scaling policy.
Provisioned concurrency runs continually and is billed in addition to standard invocation costs.
Success and Failure Destinations
Lambda asynchronous invocations can put an event or message on Amazon Simple Notification Service (SNS), Amazon Simple Queue Service (SQS), or Amazon EventBridge for further processing.
With Destinations, you can route asynchronous function results as an execution record to a destination resource without writing additional code.
An execution record contains details about the request and response in JSON format including version, timestamp, request context, request payload, response context, and response payload.
For each execution status such as Success or Failure you can choose one of four destinations: another Lambda function, SNS, SQS, or EventBridge. Lambda can also be configured to route different execution results to different destinations.
On-Success:
- When a function is invoked successfully, Lambda routes the record to the destination resource for every successful invocation.
- You can use this to monitor the health of your serverless applications via execution status or build workflows based on the invocation result.
On-Failure:
- Destinations gives you the ability to handle the Failure of function invocations along with their Success.
- When a function invocation fails, such as when retries are exhausted or the event age has been exceeded (hitting its TTL),
- Destinations routes the record to the destination resource for every failed invocation for further investigation or processing.
- Destinations provide more useful capabilities than Dead Letter Queues (DLQs) by passing additional function execution information, including code exception stack traces, to more destination services.
- Destinations and DLQs can be used together and at the same time although Destinations should be considered a more preferred solution.
Dead Letter Queue (DLQ)
You can configure a dead letter queue (DLQ) on AWS Lambda to give you more control over message handling for all asynchronous invocations, including those delivered via AWS events (S3, SNS, IoT, etc)..
A dead-letter queue saves discarded events for further processing. A dead-letter queue acts the same as an on-failure destination in that it is used when an event fails all processing attempts or expires without being processed.
However, a dead-letter queue is part of a function’s version-specific configuration, so it is locked in when you publish a version. On-failure destinations also support additional targets and include details about the function’s response in the invocation record.
You can setup a DLQ by configuring the ‘DeadLetterConfig’ property when creating or updating your Lambda function.
You can provide an SQS queue or an SNS topic as the ‘TargetArn’ for your DLQ, and AWS Lambda will write the event object invoking the Lambda function to this endpoint after the standard retry policy (2 additional retries on failure) is exhausted.
Lambda Layers
You can configure your Lambda function to pull in additional code and content in the form of layers.
A layer is a ZIP archive that contains libraries, a custom runtime, or other dependencies.
With layers, you can use libraries in your function without needing to include them in your deployment package.
A function can use up to 5 layers at a time.
Layers are extracted to the /opt directory in the function execution environment.
Each runtime looks for libraries in a different location under /opt, depending on the language.
Lambda@Edge
Lambda@Edge allows you to run code across AWS locations globally without provisioning or managing servers, responding to end users at the lowest network latency.
Lambda@Edge lets you run Node.js and Python Lambda functions to customize content that CloudFront delivers, executing the functions in AWS locations closer to the viewer.
The functions run in response to CloudFront events, without provisioning or managing servers. You can use Lambda functions to change CloudFront requests and responses at the following points:
- After CloudFront receives a request from a viewer (viewer request).
- Before CloudFront forwards the request to the origin (origin request).
- After CloudFront receives the response from the origin (origin response).
- Before CloudFront forwards the response to the viewer (viewer response).
You just upload your Node.js code to AWS Lambda and configure your function to be triggered in response to an Amazon CloudFront request.
The code is then ready to execute across AWS locations globally when a request for content is received, and scales with the volume of CloudFront requests globally.
Lambda and Amazon VPC
You can connect a Lambda function to private subnets in a VPC.
Lambda needs the following VPC configuration information so that it can connect to the VPC:
- Private subnet ID.
- Security Group ID (with required access).
Lambda uses this information to setup an Elastic Network Interface (ENI) using an available IP address from your private subnet.
Lambda functions provide access only to a single VPC. If multiple subnets are specified, they must all be in the same VPC.
Lambda functions configured to access resources in a particular VPC will not have access to the Internet as a default configuration.
If you need access to the internet, you will need to create a NAT in your VPC to forward this traffic and configure your security group to allow this outbound traffic.
Careful with DNS resolution of public hostnames as it could add to function running time (cost).
Cannot connect to a dedicated tenancy VPC.
Exam tip: If a Lambda function needs to connect to a VPC and needs Internet access, make sure you connect to a private subnet that has a route to a NAT Gateway (the NAT Gateway will be in a public subnet).
Lambda uses your function’s permissions to create and manage network interfaces. To connect to a VPC, your function’s execution role must have the following permissions:
- ec2:CreateNetworkInterface
- ec2:DescribeNetworkInterfaces
- ec2:DeleteNetworkInterface
These permissions are included in the AWSLambdaVPCAccessExecutionRole managed policy.
Only connect to a VPC if you need to as it can slow down function execution.
Building Lambda Apps
You can deploy and manage your serverless applications using the AWS Serverless Application Model (AWS SAM).
AWS SAM is a specification that prescribes the rules for expressing serverless applications on AWS.
This specification aligns with the syntax used by AWS CloudFormation today and is supported natively within AWS CloudFormation as a set of resource types (referred to as “serverless resources”).
You can automate your serverless application’s release process using AWS CodePipeline and AWS CodeDeploy.
You can enable your Lambda function for tracing with AWS X-Ray.
Elastic Load Balancing
Application Load Balancers (ALBs) support AWS Lambda functions as targets.
You can register your Lambda functions as targets and configure a listener rule to forward requests to the target group for your Lambda function.
Exam tip: Functions can be registered to target groups using the API, AWS Management Console or the CLI.
When the load balancer forwards the request to a target group with a Lambda function as a target, it invokes your Lambda function and passes the content of the request to the Lambda function, in JSON format.
Limits:
- The Lambda function and target group must be in the same account and in the same Region.
- The maximum size of the request body that you can send to a Lambda function is 1 MB.
- The maximum size of the response JSON that the Lambda function can send is 1 MB.
- WebSockets are not supported. Upgrade requests are rejected with an HTTP 400 code.
By default, health checks are disabled for target groups of type lambda.
You can enable health checks to implement DNS failover with Amazon Route 53. The Lambda function can check the health of a downstream service before responding to the health check request.
If you create the target group and register the Lambda function using the AWS Management Console, the console adds the required permissions to your Lambda function policy on your behalf.
Otherwise, after you create the target group and register the function using the AWS CLI, you must use the add-permission command to grant Elastic Load Balancing permission to invoke your Lambda function.
Lambda Limits
Memory – minimum 128 MB, maximum 10,240 MB in 1 MB increments.
Ephemeral disk capacity (/tmp space) per invocation – 512 MB.
Size of environment variables maximum 4 KB.
Number of file descriptors – 1024.
Number of processes and threads (combined) – 1024.
Maximum execution duration per request – 900 seconds.
Concurrent executions per account – 1000 (soft limit).
Function burst concurrency 500 -3000 (region dependent).
Invocation payload:
- Synchronous 6 MB.
- Asynchronous 256 KB
Lambda function deployment size is 50 MB (zipped), 250 MB unzipped.
Operations and Monitoring
Lambda automatically monitors Lambda functions and reports metrics through CloudWatch.
Lambda tracks the number of requests, the latency per request, and the number of requests resulting in an error.
You can view the request rates and error rates using the AWS Lambda Console, the CloudWatch console, and other AWS resources.
You can use AWS X-Ray to visualize the components of your application, identify performance bottlenecks, and troubleshoot requests that resulted in an error.
Your Lambda functions send trace data to X-Ray, and X-Ray processes the data to generate a service map and searchable trace summaries.
The AWS X-Ray Daemon is a software application that gathers raw segment data and relays it to the AWS X-Ray service.
The daemon works in conjunction with the AWS X-Ray SDKs so that data sent by the SDKs can reach the X-Ray service.
When you trace your Lambda function, the X-Ray daemon automatically runs in the Lambda environment to gather trace data and send it to X-Ray.
Must have permissions to write to X-Ray in the execution role.
Development Best Practices
Perform one-off time-consuming tasks outside of the function handler, e.g.:
- Connect to databases.
- Initialize the AWS SDK.
- Pull in dependencies or datasets.
Use environment variables for:
- Connection strings, S3 bucket etc.
- Passwords and other sensitive data (can be encrypted with KMS).
Minimize deployment packages size to runtime necessities.
- Break down the function if required.
- Remember the Lambda limits.
Avoid using recursive code, never have a Lambda function call itself.
Don’t put you Lambda function in a VPC unless you need to (can take longer to initialize).
Charges
Priced based on:
- Number of requests.
- Duration of the request calculated from the time your code begins execution until it returns or terminates.
- The amount of memory allocated to the function.


