

Amazon EC2 Auto Scaling
Please use the menu below to navigate the article sections:

AWS Auto Scaling monitors your applications and automatically adjusts capacity to maintain steady, predictable performance at the lowest possible cost.
AWS Auto Scaling refers to a collection of Auto Scaling capabilities across several AWS services.
The services within the AWS Auto Scaling family include:
- Amazon EC2 (known as Amazon EC2 Auto Scaling).
- Amazon ECS.
- Amazon DynamoDB.
- Amazon Aurora.
This page is specifically for Amazon EC2 Auto Scaling – Auto Scaling will also be discussed for the other services on their respective pages.
Amazon EC2 Auto Scaling Features
Amazon EC2 Auto Scaling helps you ensure that you have the correct number of Amazon EC2 instances available to handle the load for your application.
You create collections of EC2 instances, called Auto Scaling groups.
Automatically provides horizontal scaling (scale-out) for your instances.
Triggered by an event of scaling action to either launch or terminate instances.
Availability, cost, and system metrics can all factor into scaling.
Auto Scaling is a region-specific service.
Auto Scaling can span multiple AZs within the same AWS region.
Auto Scaling can be configured from the Console, CLI, SDKs and APIs.
There is no additional cost for Auto Scaling, you just pay for the resources (EC2 instances) provisioned.
Auto Scaling works with ELB, CloudWatch and CloudTrail.
You can determine which subnets Auto Scaling will launch new instances into.
Auto Scaling will try to distribute EC2 instances evenly across AZs.
Launch configuration is the template used to create new EC2 instances and includes parameters such as instance family, instance type, AMI, key pair, and security groups.
You cannot edit a launch configuration once defined.
A launch configuration:
- Can be created from the AWS console or CLI.
- You can create a new launch configuration, or.
- You can use an existing running EC2 instance to create the launch configuration.
- The AMI must exist on EC2.
- EC2 instance tags and any additional block store volumes created after the instance launch will not be considered.
- If you want to change your launch configurations you have to create a new one, make the required changes, and use that with your auto scaling groups.
You can use a launch configuration with multiple Auto Scaling Groups (ASG).
Launch templates are similar to launch configurations and offer more options (more below).
An Auto Scaling Group (ASG) is a logical grouping of EC2 instances managed by an Auto Scaling Policy.
An ASG can be edited once defined.
You can attach one or more classic ELBs to your existing ASG.
You can attach one or more Target Groups to your ASG to include instances behind an ALB.
The ELBs must be in the same region.
Once you do this any EC2 instance existing or added by the ASG will be automatically registered with the ASG defined ELBs.
If adding an instance to an ASG would result in exceeding the maximum capacity of the ASG the request will fail.
You can add a running instance to an ASG if the following conditions are met:
- The instance is in a running state.
- The AMI used to launch the instance still exists.
- The instance is not part of another ASG.
- The instance is in the same AZs for the ASG.
Scaling Options
The scaling options define the triggers and when instances should be provisioned/de-provisioned.
There are four scaling options:
- Maintain – keep a specific or minimum number of instances running.
- Manual – use maximum, minimum, or a specific number of instances.
- Scheduled – increase or decrease the number of instances based on a schedule.
- Dynamic – scale based on real-time system metrics (e.g. CloudWatch metrics).
- Predictive – machine learning to schedule the right number of EC2 instances in anticipation of approaching traffic changes.
The following table describes the scaling options available and when to use them:
| Scaling | Description | When to use |
| Maintain | Ensures the required number of instances are running | Use when you always need a known number of instances running at all times |
| Manual | Manually change desired capacity | Use when your needs change rarely enough that you’re ok the make manual changes |
| Scheduled | Adjust min/max on specific dates/times or recurring time periods | Use when you know when your busy and quiet times are. Useful for ensuring enough instances are available before very busy times |
| Dynamic | Scale in response to system load or other triggers using metrics | Useful for changing capacity based on system utilization, e.g. CPU hits 80%. |
| Predictive | predict capacity required ahead of time using ML | Useful for when capacity, and number of instances is unknown. |
Scheduled Scaling
Scaling based on a schedule allows you to scale your application ahead of predictable load changes.
For example, you may know that traffic to your application is highest between 9am and 12pm Monday-Friday.
Dynamic Scaling
Amazon EC2 Auto Scaling enables you to follow the demand curve for your applications closely, reducing the need to manually provision Amazon EC2 capacity in advance.
For example, you can track the CPU utilization of your EC2 instances or the “Request Count Per Target” to track the number of requests coming through an Application Load Balancer.
Amazon EC2 Auto Scaling will then automatically adjust the number of EC2 instances as needed to maintain your target.
Predictive Scaling
Predictive Scaling uses machine learning to schedule the optimum number of EC2 instances in anticipation of upcoming traffic changes.
Predictive Scaling predicts future traffic, including regularly occurring spikes, and provisions the right number of EC2 instances in advance.
Predictive Scaling uses machine learning algorithms to detect changes in daily and weekly patterns and then automatically adjust forecasts.
You can configure the scaling options through Scaling Policies which determine when, if, and how the ASG scales out and in.
The following table describes the scaling policy types available for dynamic scaling policies and when to use them (more detail further down the page):
| Scaling Policy | What it is | When to use |
| Target Tracking Policy | Adds or removes capacity as required to keep the metric at or close to the specific target value. | You want to keep the CPU usage of your ASG at 70% |
| Simple Scaling Policy | Waits for the health check and cool down periods to expire before re-evaluating | Useful when load is erratic. AWS recommends step scaling instead of simple in most cases. |
| Step Scaling Policy | Increases or decreases the configured capacity of the Auto Scaling group based on a set of scaling adjustments, known as step adjustments. | You want to vary adjustments based on the size of the alarm breach |
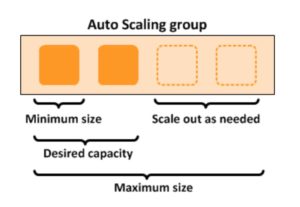
The diagram below depicts an Auto Scaling group with a Scaling policy set to a minimum size of 1 instance, a desired capacity of 2 instances, and a maximum size of 4 instances:
Scaling based on Amazon SQS
Can also scale based on an Amazon Simple Queue Service (SQS) queue.
This comes up as an exam question for SAA-C02.
Uses a custom metric that’s sent to Amazon CloudWatch that measures the number of messages in the queue per EC2 instance in the Auto Scaling group.
A target tracking policy configures your Auto Scaling group to scale based on the custom metric and a set target value. CloudWatch alarms invoke the scaling policy.
A custom “backlog per instance” metric is used to track the number of messages in the queue and also the number available for retrieval.
Can base the adjustments off the SQS Metric “ApproximateNumberOfMessages”.
Launch Templates vs Launch Configurations
Launch templates are like launch configurations in that they specify the instance configuration information.
Information includes the ID of the Amazon Machine Image (AMI), the instance type, a key pair, security groups, and the other parameters that you use to launch EC2 instances.
Launch templates include additional features such as supporting multiple versions of a template.
With versioning, you can create a subset of the full set of parameters and then reuse it to create other templates or template versions.
EC2 Auto Scaling Lifecycle Hooks
Lifecycle pause EC2 instances as an Auto Scaling group launches or terminates them so you can perform custom actions.
Paused instances remain in a wait state either until you complete the lifecycle action using the complete-lifecycle-action command or the CompleteLifecycleAction operation, or until the timeout period ends (one hour by default).
Lifecycle hooks provide greater control over how instances launch and terminate.
You can send notifications when an instance enters a wait state using Amazon EventBridge, Amazon SNS, or Amazon SQS to receive the notifications.
High Availability
Amazon EC2 Auto Scaling offers high availability (HA) when instances are launched into at least two Availability Zones.
You can use an Amazon Elastic Load Balancer or Amazon Route 53 to direct incoming connections to your EC2 instances.
EC2 Auto Scaling cannot provide HA across multiple AWS Regions as it is a regional service.
Monitoring and Reporting
When Auto Scaling group metrics are enabled the Auto Scaling group sends sampled data to CloudWatch every minute (no charge).
You can enable and disable Auto Scaling group metrics using the AWS Management Console, AWS CLI, or AWS SDKs.
The AWS/AutoScaling namespace includes the following metrics which are sent to CloudWatch every 1 minute:
- GroupMinSize
- GroupMaxSize
- GroupDesiredCapacity
- GroupInServiceInstances
- GroupPendingInstances
- GroupStandbyInstances
- GroupTerminatingInstances
- GroupTotalInstances
Metrics are also sent from the Amazon EC2 instances to Amazon CloudWatch:
- Basic monitoring sends EC2 metrics to CloudWatch about ASG instances every 5 minutes.
- Detailed monitoring can be enabled and sends metrics every 1 minute (chargeable).
- If the launch configuration is created from the console basic monitoring of EC2 instances is enabled by default.
- If the launch configuration is created from the CLI detailed monitoring of EC2 instances is enabled by default.
EC2 Auto Scaling uses health checks to check if instances are healthy and available.
- By default Auto Scaling uses EC2 status checks.
- Auto Scaling supports ELB health checks and custom health checks in addition to the EC2 status checks.
- If any of the configured health checks returns an unhealthy status the instance will be terminated.
- With ELB health checks enabled an instance is marked as unhealthy if the ELB reports it as OutOfService.
- A healthy instance enters the InService state.
- If an EC2 instance is marked as unhealthy it will be scheduled for replacement.
- If connection draining is enabled, EC2 Auto Scaling will wait for any in-flight requests to complete or timeout before terminating instances.
- The health check grace period is a period of time in which a new instance is allowed to warm up before health check are performed (300 seconds by default).
Note: When using Elastic Load Balancers it is an AWS best practice to enable the ELB health checks. If you don’t, EC2 status checks may show an instance as being healthy that the ELB has determined is unhealthy. In this case the instance will be removed from service by the ELB but will not be terminated by Auto Scaling.
Logging and Auditing
AWS CloudTrail captures all API calls for AWS Auto Scaling as events.
The API calls that are captured include calls from the Amazon EC2 Auto Scaling console and code calls to the AWS Auto Scaling API.
If you create a trail, you can enable continuous delivery of CloudTrail events to an Amazon S3 bucket, including events for AWS Auto Scaling.
If you don’t configure a trail, you can still view the most recent (up to 90 days) events in the CloudTrail console in the Event history.
CloudTrail events include the calls made to AWS Auto Scaling, the IP address from which the requests were made, who made the requests, when they were made, and additional details.
EC2 Auto Scaling support identity-based IAM policies.
Amazon EC2 Auto Scaling does not support resource-based policies.
Amazon EC2 Auto Scaling uses service-linked roles for the permissions that it requires to call other AWS services on your behalf.
A service-linked role is a unique type of IAM role that is linked directly to an AWS service.
There is a default service-linked role for your account, named AWSServiceRoleForAutoScaling.
This role is automatically assigned to your Auto Scaling groups unless you specify a different service-linked role.
Amazon EC2 Auto Scaling also does not support Access Control Lists (ACLs).
You can apply tag-based, resource-level permissions in the identity-based policies that you create for Amazon EC2 Auto Scaling.
This offers better control over which resources a user can create, modify, use, or delete.
ASG Behavior and Configuration
EC2 Auto Scaling – Termination Policy:
- Termination policies control the instances which are terminated first when a scale-in event occurs.
- There is a default termination policy configured and you can create your own customized termination policies.
- The default termination policy helps to ensure that EC2 instances span Availability Zones evenly for high availability.
- The default policy is fairly generic and flexible to cover a range of scenarios.
You can enable Instance Protection which prevents Auto Scaling from scaling in and terminating the EC2 instances.
If Auto Scaling fails to launch instances in a specific AZ it will try other AZs until successful.
The default health check grace period is 300 seconds.
“Scaling out” is the process in which EC2 instances are launched by the scaling policy.
“Scaling in” is the process in which EC2 instances are terminated by the scaling policy.
It is recommended to create a scale-in event for every configured scale-out event.
An imbalance may occur due to:
- Manually removing AZs/subnets from the configuration.
- Manually terminating EC2 instances.
- EC2 capacity issues.
- Spot price is reached.
All Elastic IPs and EBS volumes are detached from terminated EC2 instances and will need to be manually reattached.
Using custom health checks a CLI command can be issued to set the instance’s status to unhealthy, e.g.:
aws autoscaling set–instance-health –instance-id i-123abc45d –health-status Unhealthy
Once an EC2 instance enters the terminating state it cannot be put back into service again.
However, there is a short period of time in which an AWS CLI command can be run to change an instance to healthy.
Termination of unhealthy instances happens first, then Auto Scaling attempts to launch new instances to replace terminated instances. This is different to AZ rebalancing.
You can use the AWS Console or AWS CLI to manually remove (detach) instances from an ASG.
When detaching an EC2 instance you can optionally decrement the ASG’s desired capacity (to prevent it from launching another instance).
An instance can only be attached to one Auto Scaling group at a time.
You can suspend and then resume one or more of the scaling processes for your ASG at any time.
This can be useful when if want to investigate an issue with an application and make changes without invoking the scaling processes.
You can manually move an instance from an ASG and put it in the standby state.
Instances in the standby state are still managed by Auto Scaling, are charged as normal, and do not count towards available EC2 instance for workload/application use.
Auto scaling does not perform any health checks on EC2 instances in the standby state.
Standby state can be used for performing updates/changes/troubleshooting etc. without health checks being performed or replacement instances being launched.
When you delete an Auto Scaling group all EC2 instances will be terminated.
You can select to use Spot instances in launch configurations.
The ASG treats spot instances the same as on-demand instances.
You can mix Spot instances with on-demand (when using launch templates).
The ASG can be configured to send an Amazon SNS notification when:
- An instance is launched.
- An instance is terminated.
- An instance fails to launch.
- An instance fails to terminate.
Merging ASGs.
- Can merge multiple single AZ Auto Scaling Groups into a single multi-AZ ASG.
- Merging can only be performed by using the CLI.
- The process is to rezone one of the groups to cover/span the other AZs for the other ASGs and then delete the other ASGs.
- This can be performed on ASGs with or without ELBs attached to them.
Cooldown Period:
- The cooldown period is a setting you can configure for your Auto Scaling group that helps to ensure that it doesn’t launch or terminate additional instances before the previous scaling activity takes effect.
- A default cooldown period of 300 seconds is applied when you create your Auto Scaling group.
- You can configure the cooldown period when you create the Auto Scaling group.
- You can override the default cooldown via scaling-specific cooldown.
The warm-up period is the period in which a newly launched EC2 instance in an ASG that uses step scaling is not considered toward the ASG metrics.


